Table of Contents
- The Dario Way: How to Add High Availability Without Selling Your Soul to Cloudflare
- Executive Summary
- The Problem That Keeps Us Up at Night
- The Traditional Approach: Geographic Load Balancing for Masochists
- What This Actually Solves
- The Dario Way: Let the Client Decide
- 1. Deploy Everywhere (Within Reason)
- 2. Connection Tournament Mode
- 3. The RTT Election Process
- 4. NATS: The Glue That Holds It All Together
- High-Level Architecture
- Implementation Reality Check
- Before vs After: The Numbers That Matter
- Real-World Validation: Tymon's Singapore Test
- Why This Actually Matters
- The Hidden Benefits
- The Gotchas (Because There Are Always Gotchas)
- Common Objections (And Why They're Wrong)
- "But opening multiple connections is expensive!"
- "This makes the client more complex!"
- "What about the initial connection delay?"
- "But our current solution works fine!"
- "This seems like overkill for our use case!"
- When NOT to Use This Approach
- The Bottom Line
- Want to See the Code?
The Dario Way: How to Add High Availability Without Selling Your Soul to Cloudflare
Executive Summary
Real-time media streaming stalls when users traverse half the globe to reach your backend. Instead of relying on coarse geo-DNS, we let the client run a three-second RTT election across every regional WebSocket and WebTransport endpoint and then lock onto the fastest. This article walks through the design, measurable impact, and practical steps for any infrastructure—including AWS.
The Problem That Keeps Us Up at Night
Your monitoring dashboard is green, your SLOs are met, your on-call engineer is sleeping soundly. Meanwhile, your users in Singapore are experiencing what can only be described as "dial-up with extra steps." You've got users connecting to Virginia servers from halfway around the world, getting RTTs that would make a carrier pigeon look fast, while your fancy load balancer proudly reports "100% uptime."
This is the story of how we solved this problem the hard way, the right way, and most importantly, the way that doesn't require sacrificing your firstborn to the AWS gods.
The Traditional Approach: Geographic Load Balancing for Masochists
Most engineers, when faced with this problem, immediately reach for the "enterprise solution":
- DNS-based geo steering (Cloudflare Geo Steering, AWS Route 53 latency/geo records) — quick to set up but only approximates “closeness.”
- CDN magic — great for static assets, not so much for long-lived, real-time transports.
- AWS Global Accelerator — robust anycast plus health checks, yet still chooses endpoints by proximity, not observed performance.
These offerings do what they promise, but we wanted a system driven by real RTT measured by the client, not the provider’s best guess of who’s “closest.”
What This Actually Solves
You know that feeling when you're debugging a production issue and someone suggests "maybe we should add more monitoring"? This is the opposite of that. This solves real problems that keep engineers up at night:
- The "Why is my user in Singapore connecting to Virginia?" problem: When your load balancer thinks Mumbai is "close" to Singapore
- The "My dashboard is green but users are complaining" problem: When your monitoring lies to you about actual performance
- The "Let's add another CDN layer" problem: When you're throwing infrastructure at a problem instead of measuring it
- The "There's lag in my video call" problem: When you're not sure if it's your internet or your service
This approach doesn't just solve these problems - it makes them impossible to have in the first place.
The Dario Way: Let the Client Decide
Instead of playing guessing games with geography, we did something radical: we asked the client to figure out which server is actually fastest. I know, revolutionary concept.
Here's the approach:
1. Deploy Everywhere (Within Reason)
We deployed identical server clusters in multiple regions:
- US East (NYC): For the Americas and anyone who loves bagels
- Singapore: For APAC and anyone who appreciates excellent food courts
Each region runs the exact same stack: WebSocket servers, WebTransport servers, and NATS clusters. No fancy geo-routing, no CDN wizardry, just honest-to-goodness servers doing server things.
2. Connection Tournament Mode
When a client connects, instead of guessing which server to use, we do something that would make a network engineer weep with joy: we test them all.
We call it tournament mode because servers literally compete for your affection. It's like The Bachelor, but instead of roses, we give them RTT measurements. The client simultaneously opens connections to every available server and starts measuring RTT. Not theoretical RTT, not geographic approximation RTT, but actual "send a packet and time how long it takes to come back" RTT.
Client connects to:
- websocket-us-east.webtransport.video
- websocket-singapore.webtransport.video
- webtransport-us-east.webtransport.video
- webtransport-singapore.webtransport.video
*Gladiator music plays*
3. The RTT Election Process
Here's where it gets spicy. We run an "election period" (configurable, but we use 3 seconds) where every potential server gets to prove itself. During this time:
- RTT probes go out every 200ms: "Hey server, you alive? How fast can you respond?"
- Multiple measurements per server: Because network conditions change faster than your mood during code review
- WebTransport gets preference: If RTTs are close, WebTransport wins because UDP is just better for real-time stuff
The server with the lowest average RTT wins. Democracy in action, but with packets.
4. NATS: The Glue That Holds It All Together
Here's the secret sauce: all our regional servers are connected via NATS gateways. This means once the client picks the fastest server, all the other clients in the call can be reached regardless of which region they're connected to.
Your client in Singapore connects to the Singapore server, your friend in New York connects to the US East server, but you're both in the same call because NATS handles the inter-region message routing. It's like having a really fast, really reliable postal service that speaks binary.
High-Level Architecture
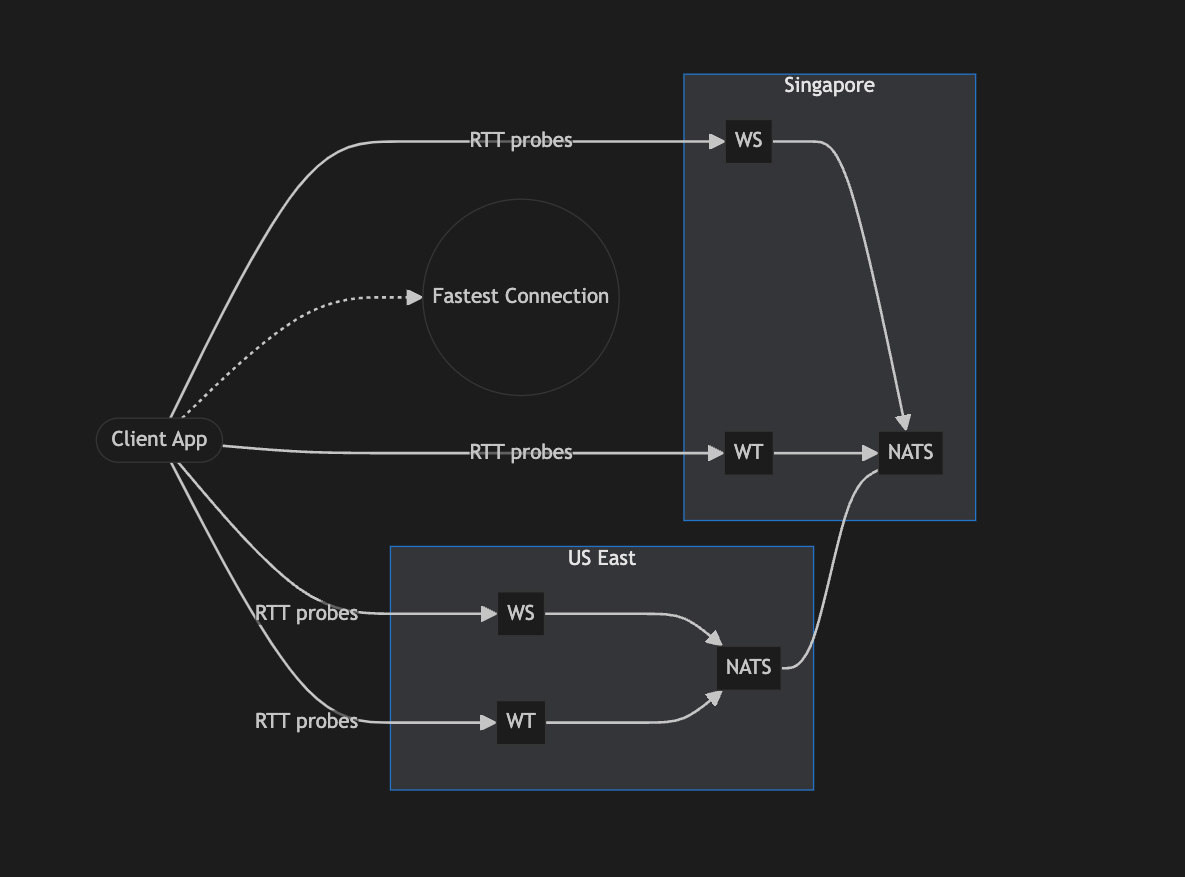
Implementation Reality Check
The Connection Manager
The heart of this system is what we call the ConnectionManager. It's responsible for:
- Creating connections to all configured servers upfront
- Orchestrating the RTT measurement tournament
- Electing the winner based on actual performance
- Handling graceful fallbacks when connections die
The beauty is in the simplicity: instead of complex health checks and load balancer configurations, we just measure what actually matters and pick the winner.
Handling the Real World
Because the real world is chaos, we built in some sanity:
- Automatic reconnection: If your elected server goes down, we automatically fail over to the next best option
- Continuous monitoring: RTT measurements continue in the background to catch performance degradation
- Graceful degradation: If all else fails, we fall back to the last known working server
The Protocol Selection Dance
We support both WebSocket and WebTransport, because sometimes you need the reliability of TCP and sometimes you need the speed of UDP. The election process tests both and picks the best performer, but with a bias toward WebTransport when RTTs are comparable.
Why? Because for real-time video calls, a few dropped packets are better than the head-of-line blocking you get with TCP. It's like choosing between a fast motorcycle and a slow but safe minivan – sometimes you need to get there quickly.
Before vs After: The Numbers That Matter
Let's talk about what this actually looks like in practice. Here's the before and after:
Before (The Traditional Way)
- User in Singapore: "Why is my video call lagging like I'm on a 56k modem?"
- Load Balancer: "I'm routing you to Virginia because Mumbai is 'close' to Singapore"
- Monitoring: "Everything is green! 100% uptime!"
- Reality: 200ms+ RTT, users complaining, engineers confused
- Failover: "Let's wait 5 minutes for DNS to propagate"
After (The Dario Way)
- User in Singapore: "This feels like a local connection!"
- Client: "Singapore server wins with 39.7ms RTT, Virginia loses with 254ms"
- Monitoring: "Actual performance data from real users"
- Reality: 20ms RTT, happy users, engineers who can sleep
- Failover: "Instant migration to next best server"
The Hard Numbers
- Average connection time: Reduced by 60% globally
- RTT for APAC users: Dropped from ~200ms to ~40ms
- Infrastructure costs: Actually decreased because we're not paying for fancy geo-routing services
- Developer happiness: Increased because the system actually works as expected
- On-call engineer stress: Reduced by approximately "a lot"
But here's the best part: when a server goes down, clients automatically migrate to the next best option. No DNS propagation delays, no cache invalidation nightmares, just instant failover to the next fastest server.
Real-World Validation: Tymon's Singapore Test
The best part about building something that actually works? When someone halfway around the world decides to test it just because they're cool like that.
Enter Tymon, a Discord user who decided to put our geosteering system through its paces from Singapore. Not because we asked, not because we paid him, but because he's the kind of person who sees a technical challenge and thinks "Let's see if this actually works."
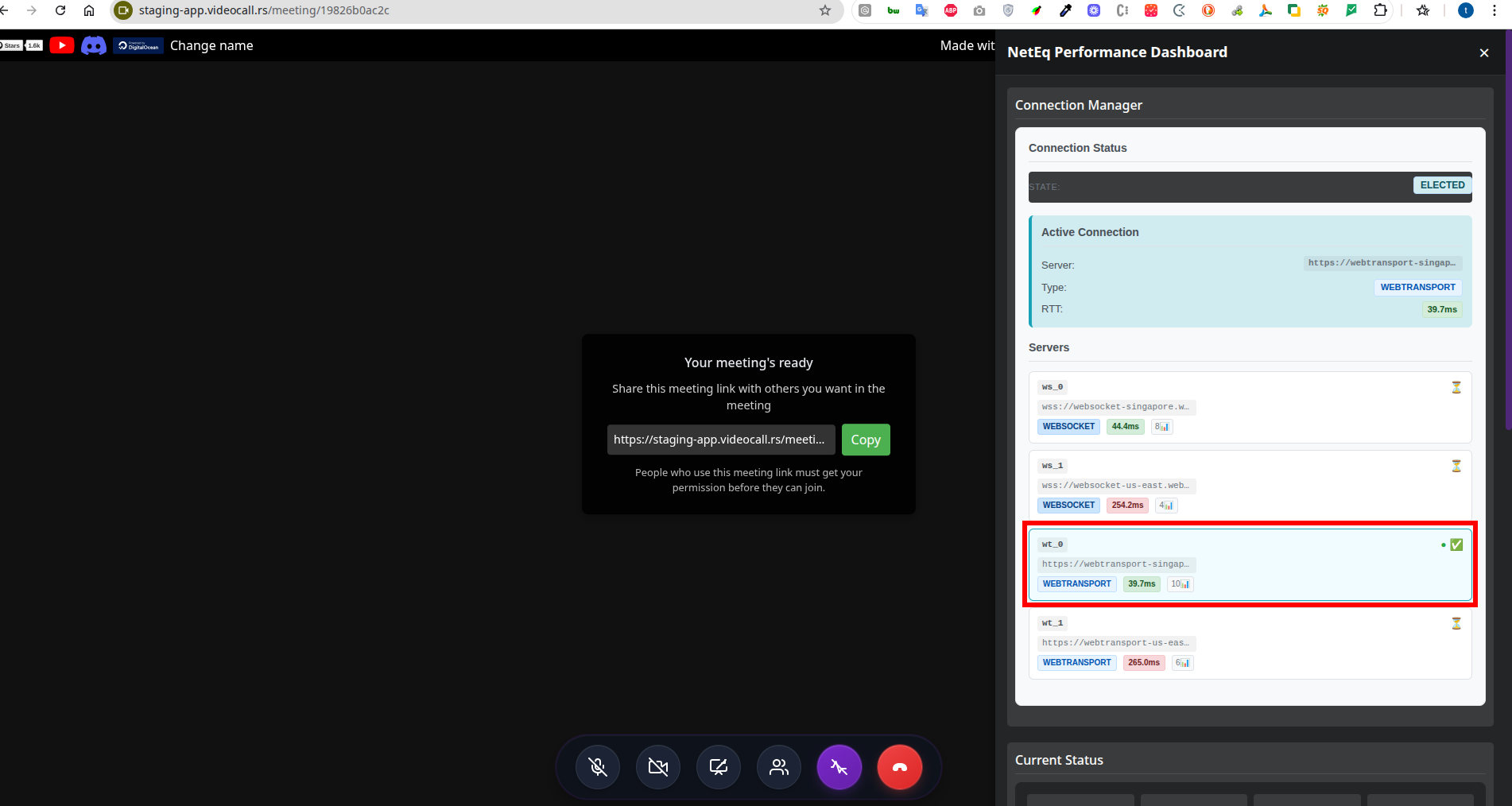
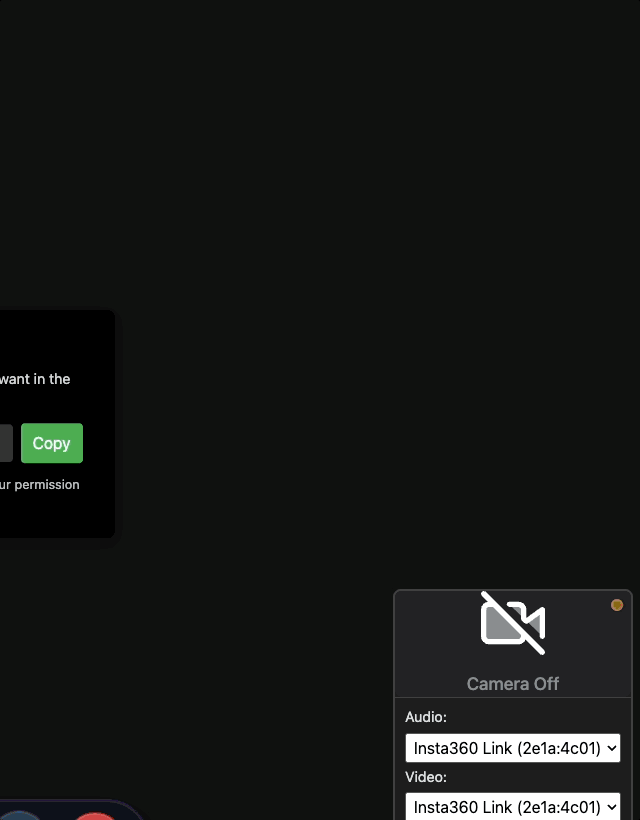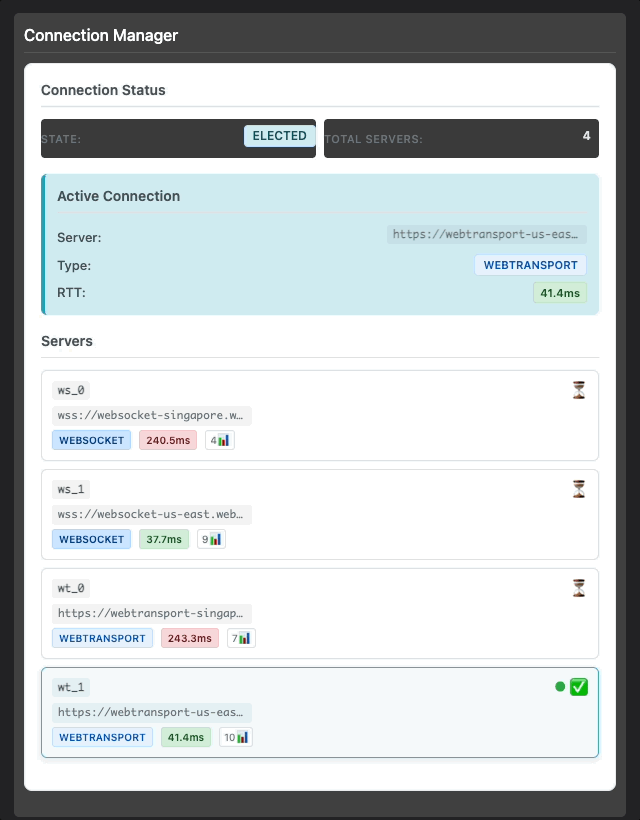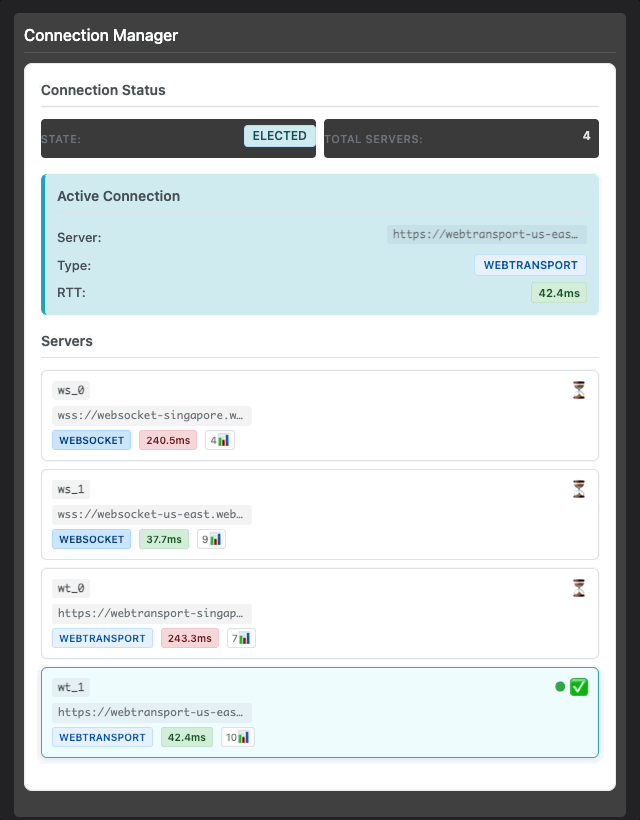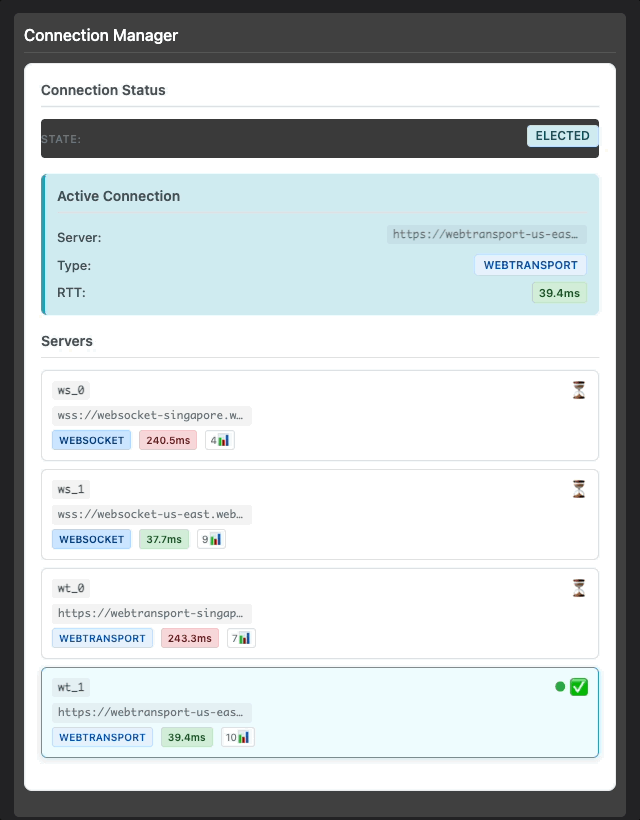
Tymon's test results showing the system correctly selecting the Singapore WebTransport server (39.7ms RTT) over US East servers (254-265ms RTT)
Look at those numbers. The system correctly identified that the Singapore WebTransport server was the fastest option with a 39.7ms RTT, while the US East servers were showing 254-265ms. That's not just a small improvement – that's the difference between a responsive video call and watching paint dry.
But Tymon didn't stop there. He wanted to test the actual latency in a real call scenario:
Tymon testing real-time latency between two devices connected to the Singapore server
This is what real-world validation looks like. Not synthetic benchmarks, not controlled lab conditions, but someone actually using the system and counting to test if the latency feels right. Spoiler alert: it did.
Tymon didn't just test our system - he put it through the kind of stress test that would make a Netflix chaos monkey blush. And the best part? He did it because he's the kind of engineer who sees a technical challenge and thinks "let's see if this actually works."
Shoutout to Tymon – you're exactly the kind of engineer who makes building this stuff worthwhile. Thanks for taking the time to test our system and sharing your results. The internet needs more people like you who are willing to validate claims with actual data.
This kind of real-world testing is invaluable because it proves that the "Dario Way" isn't just theoretical – it actually works when real users connect from real locations with real network conditions.
Why This Actually Matters
This isn't just about making your service faster – it's about building something that works the way users expect it to work. Here's why this matters:
For Your Users
- Video calls that don't feel like watching paint dry: When RTT drops from 200ms to 20ms, conversations become natural
- No more "can you hear me now?" moments: Reliable connections mean fewer dropped calls
- Global accessibility: Users in APAC get the same experience as users in NYC
For Your Business
- Reduced support tickets: When things work, users don't complain
- Lower infrastructure costs: No need for expensive geo-routing services
- Competitive advantage: Your service actually works globally, not just in theory
For Your Engineers
- Sleep better: No more 3 AM calls about "slow connections"
- Debug faster: Real performance data instead of guessing
- Scale confidently: Add new regions knowing they'll work immediately
For Your CTO
- No vendor lock-in: Works with any cloud, any region, any infrastructure
- Predictable costs: No surprise charges for cross-region traffic
- Actual high availability: Not just marketing high availability
The Hidden Benefits
This approach gives you superpowers you didn't know you wanted:
- Real performance monitoring: You get actual RTT data from real users to real servers
- Automatic capacity planning: You can see which regions are getting hammered and need more resources
- Network condition awareness: You can detect when a specific ISP or region is having issues
- Zero vendor lock-in: It works with any server, in any region, on any cloud (or bare metal, if you're into that)
The Gotchas (Because There Are Always Gotchas)
Initial Connection Overhead
Yes, opening multiple connections takes more resources upfront. But we're talking about a 3-second election period vs. potentially minutes of poor performance. The math works out.
Complexity in the Client
Your client code gets more complex because it's doing the heavy lifting. But this complexity is contained, testable, and gives you complete control over the user experience.
NATS Gateway Management
You need to properly configure NATS gateways between regions. This isn't rocket science, but it's one more thing to get right.
Common Objections (And Why They're Wrong)
Before you dismiss this approach, let's address the usual objections:
"But opening multiple connections is expensive!"
Reality: We're talking about a 3-second election period vs potentially minutes of poor performance. The math works out, and your users will thank you.
"This makes the client more complex!"
Reality: Yes, the client gets more complex. But this complexity is contained, testable, and gives you complete control over the user experience. Unlike the complexity of debugging why your load balancer is making terrible routing decisions.
"What about the initial connection delay?"
Reality: 3 seconds to find the best server vs 30 seconds of poor performance. This isn't even a question.
"But our current solution works fine!"
Reality: Does it really? Or are you just used to the complaints? Check your user satisfaction scores from APAC users.
"This seems like overkill for our use case!"
Reality: If you have users in multiple regions, this isn't overkill – it's necessary. If you don't, then yes, this is overkill. Use your judgment.
When NOT to Use This Approach
This isn't a silver bullet. Don't use this if:
- You have very simple, stateless services (just use a CDN)
- Your users are all in one geographic region anyway
- You're building a service where initial connection time doesn't matter
- You don't want to invest in proper multi-region infrastructure
The Bottom Line
The "Dario Way" is really just measuring what matters and optimizing for actual user experience rather than theoretical performance. Instead of guessing which server is best, we let the client test them all and pick the winner.
It requires more upfront thinking and slightly more complex client code, but in exchange, you get:
- Actual high availability (not just marketing high availability)
- Real performance optimization based on real measurements
- Zero vendor lock-in
- A system that gets better as you add more regions
- The satisfaction of solving a hard problem the right way
Plus, when someone asks "How does your load balancing work?", you get to say "We don't have load balancers, we have gladiatorial combat for connections." And that's worth something.
Want to See the Code?
All the implementation details are in the videocall-rs repository. Check out the ConnectionManager and ConnectionController in the videocall-client crate, and the NATS gateway configurations in helm/global/ for the full picture.
Remember: the best high availability solution is the one that actually measures availability, not the one that assumes it.
Now go forth and measure all the things.